

 Май 5th, 2014
Май 5th, 2014  Данил
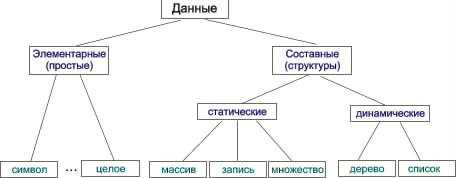
ДанилМассив структуры данных

Массив структуры данных — метод хранения подобных типов данных в линейной последовательности.Такая линейная последовательность обеспечивает очень быстрый и эффективный доступ к любой части массива.Каждый элемент данных в массиве расположен на пронумерованной позиции называемой индексом. Фактические данные,расположенные в частности,индекса называются элементами.Массивы структуры данных широко используются в большинстве языков компьютерного программирования и являются основой для многих других типов структуры данных.
Одной из основных черт массива структуры данных,то как он хранится в памяти.В большинстве случаев,массивы хранятся в линейной последовательности. Другие структуры данных, такие как связанные списки, могут иметь каждый элемент,хранящиеся в любой случайный момент в памяти, разбросанные по всей площади свободного пространства.Массив хранится в последовательности, поэтому может быть выполнен быстро ряд эффективных операций по нахождению адреса индекса в памяти и извлечение данных.
Существуют различные способы, чтобы объявить массив структуры данных.Наиболее простая форма-это одномерный массив,который начинается с нулевого показателя,и может иметь по мере необходимости многие индексы.Двумерный массив имеет два индекса,если на них ссылаются,подобно ширине и высоте для монтажа на сетке координат.Многомерные массивы могут иметь три или более индексов в массиве. Хотя массив осуществляется с более чем одним указателем справочных данных,он по прежнему сохраняется линейно в памяти.
Массивы отличаются от других структур данных,таких, как связанные списки.Связанный список — это динамичная структура, которая может увеличивается и уменьшается,пока программа выполняется.По большей части, массивы являются статическими и их размеры не могут быть изменены во время выполнения.Это означает, что массив ограничивает количество элементов, которые можно сохранить во время выполнения. Наоборот, массив позволяет полностью произвольный доступ к элементам, которые он содержит,в отличие от связанных списков,которые должны быть прочитаны в последовательности,чтобы добраться до элементов в середине и в конце.
Скорость массива структуры данных,делает его вполне подходящим для использования в других,более сложных типах данных,таких как хэш-таблицы.Предсказуемость элементов адреса памяти,также может быть использована для реализации очень быстрого массива сращивания алгоритмов,которые позволяют быстро перемещать данные.Это особенно полезно для операций сортировки,которые идеально подходят для использования с массивами.
[share-locker locker_id=»ed18cf542e63e40bd» theme=»blue» message=»Если Вам понравилась эта статья,нажмите на одну из кнопок ниже.СПАСИБО!» facebook=»true» likeurl=»CURRENT» vk=»true» vkurl=»CURRENT» google=»true» googleurl=»CURRENT» tweet=»true» tweettext=»» tweeturl=»CURRENT» follow=»true» linkedin=»true» linkedinurl=»CURRENT» ][/share-locker]
 Опубликовано в
Опубликовано в  :
: